parDist
Feb 9, 2018 #parallelDist
Problem Statement:
We have a large dataset. We need to compute its distance matrix (i.e. for clustering purposes). The complexity for a N * P matrix is
N(N-1)/2 * 3P
Create Sample
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionpts <- rnorm(1e4, mean = c(5, 5, 10, 10, 15, 15), sd = 1) %>% matrix(ncol = 2, byrow = T)
pts %>% plot(xlab = "x", ylab = "y")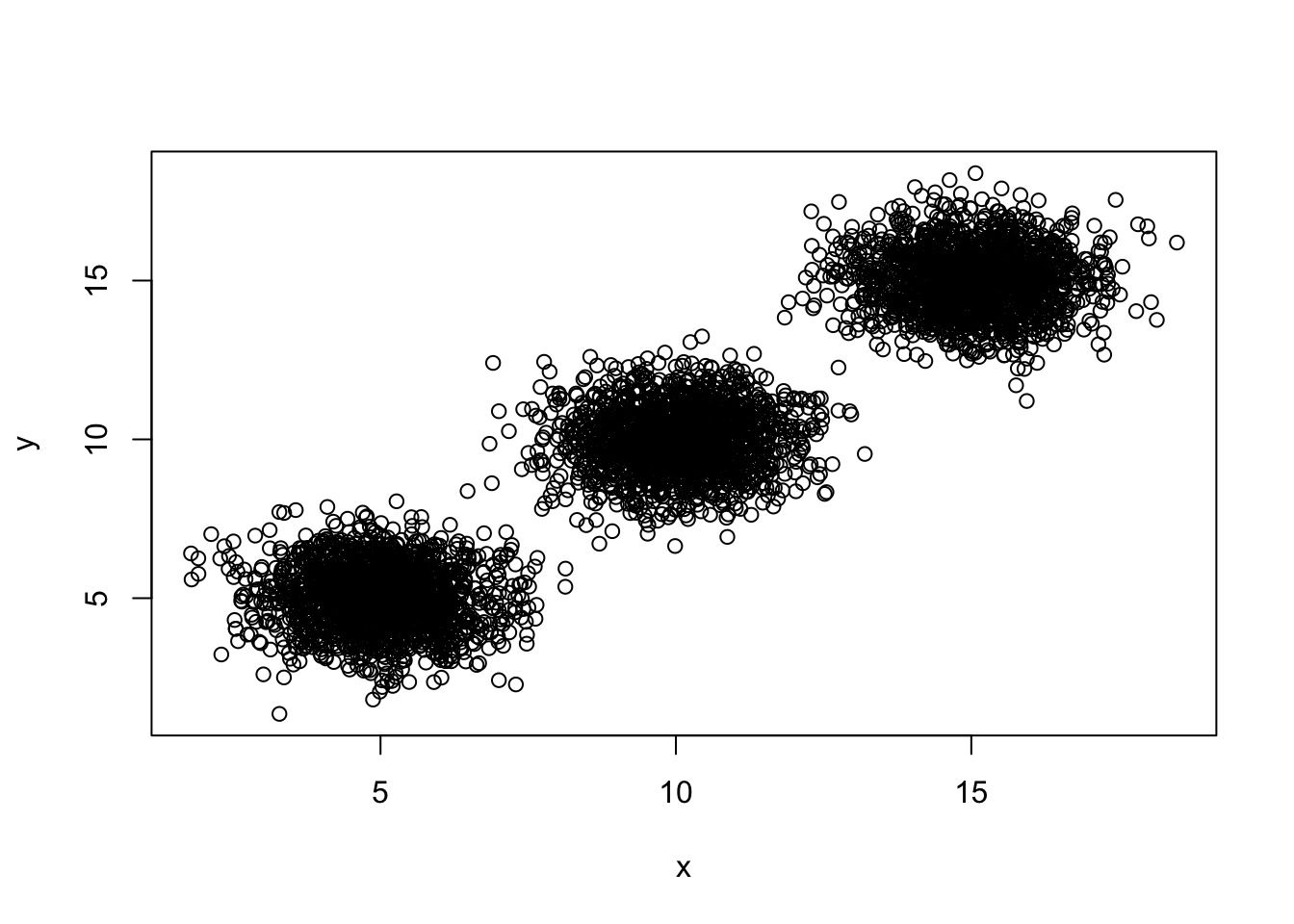
Package ‘parallelDist’
parallelDist is a fast parallelized alternative to R’s native dist function. The package is mainly implemented in C++ and leverages the RcppParellel package to parallelize the distance computations. In addition, it also uses Armadillo linear algebra library to optimize matrix operations during distance calculations.
In short, to compute distance matrix for large data object, use parallelDist because it is much faster.
Demo
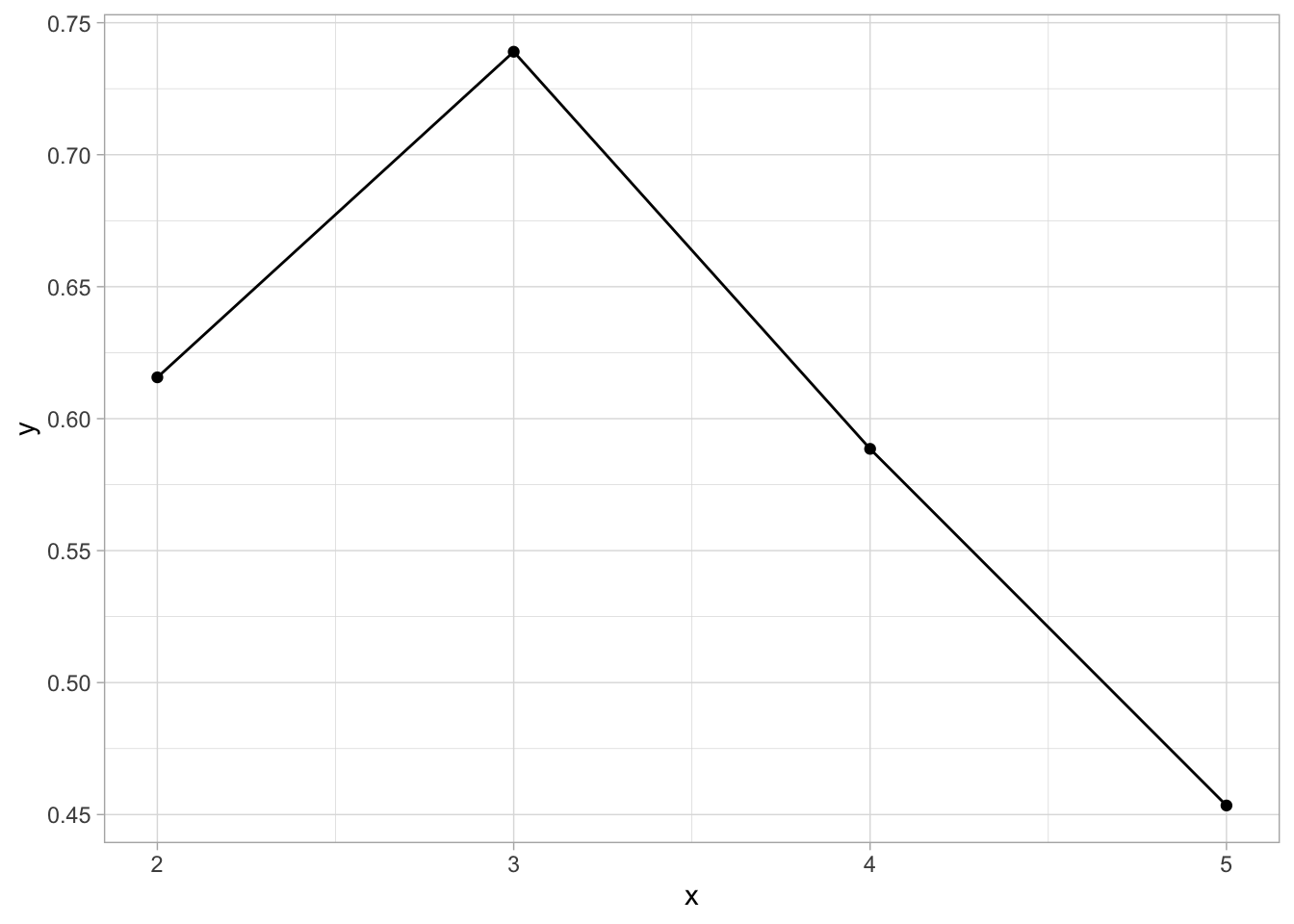
Say we wish to compute distance matrix to compute silhouette distance for sample points above to determine the optimal number of cluster (which we already knew is 3).
# By default, parDist returns a dist object
# Here we convert to matrix for minor efficiency
dist.euclidean <- parallelDist::parDist(pts, method = "euclidean") %>% as.matrix()
# A custom function for looping
compare_silhouette <- function(k){
kmeans(pts, centers = k, nstart = 20, iter.max = 50)$cluster %>%
# use dmatrix instead of dist
cluster::silhouette(dmatrix = dist.euclidean) %>%
summary() %>%
# extract avergae silhouette width
`[[`('avg.width')
}
# Here we try out various number of clusters
res <- lapply(2:5, compare_silhouette)
library(ggplot2)
data.frame(x = 2:5, y = unlist(res)) %>% ggplot(aes(x, y)) + geom_line() + geom_point() + theme_light()